BOSTON, Jan. 20, 2026 (GLOBE NEWSWIRE) -- Modulate, the frontier conversational voice intelligence company, announced today new breakthrough research: the Ensemble Listening Model (ELM), a new approach to artificial intelligence which outperforms foundation models like LLMs on accuracy and cost.
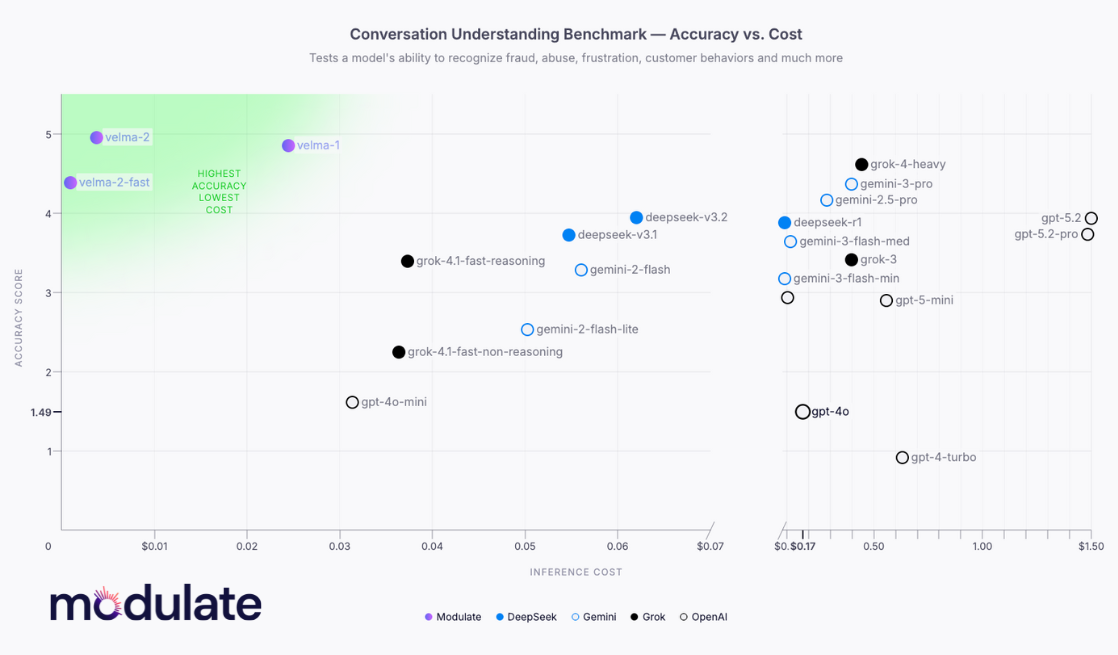
Modulate’s new ELM, Velma 2.0, combines spoken words with acoustic signals like emotion, prosody, timbre, and background noise to understand the true meaning of each voice conversation. Existing voice architectures, which “flatten” audio into text transcripts, lose this multi-dimensional nature and struggle with the nuance of voice. According to Modulate benchmarks, the newly released Velma 2.0 is the top-performing AI model for conversation understanding, outpacing OpenAI, Gemini, ElevenLabs, and other market leaders.
“Most AI architectures struggle to integrate multiple perspectives from the same conversation,” said Carter Huffman, CTO and Co-Founder of Modulate. “That’s what we solved with the Ensemble Listening Model. It’s a system where dozens of diverse, specialized models work together in real-time to produce coherent, actionable insights for enterprises. This isn’t just an evolution of AI. It’s a fundamentally new way to architect enterprise intelligence for messy, human interactions.”
Velma 2.0 is live today in Modulate’s enterprise platform, powering hundreds of millions of conversations across Fortune 500 companies and leading game studios, identifying potential fraud, dissatisfied customers, rogue AI agents, abusive interactions, and much more.
AI needs a new enterprise architecture, and ELMs deliver
Despite unprecedented investment and hype, artificial intelligence has continued to fall short of enterprise needs. An estimated 95% of business attempts to deploy AI have failed over the past year, as organizations struggle with hallucinations, runaway costs, opaque decision-making, and complicated integrations into real workflows.
ELMs rely not just on one large, monolithic model, but hundreds of models coordinated in concert. Smaller ensemble architectures have long been known to offer increased accuracy and efficiency, but the complexity of managing hundreds of models prevented most developers from taking the next logical step.
Modulate broke through that barrier through a combination of ingenuity and need. Its earliest focus was in working with online games, including Call of Duty and Grand Theft Auto Online, on analyzing real-time voice conversations. Noticing the subtle differences between friendly banter and genuine hate – in a noisy, fast-moving, and jargon-filled environment – requires a complex mix of emotion understanding, timing analysis, speaker modeling, behavioral recognition, and more. In bringing together enough models to truly unpack these challenges, Modulate pushed the limits of how to orchestrate more and more models, until it had created something fundamentally new.
Modulate's approach stands in sharp contrast to the dominant paradigm for voice processing, which relies on feeding transcripts to large language models (LLMs). Because LLMs are language models that operate only on text tokens, they miss out on the other dimensions of voice (tone, emotion, pauses, etc.), resulting in an incomplete and often inaccurate picture of what’s really being said. ELMs fill this gap.
“When building technology, it’s critical to understand the problem you’re aiming to solve,” said Mike Pappas, CEO and Co-Founder of Modulate. “Enterprises need tools to turn complex, multidimensional data into reliable, structured insights — in real-time and, critically, transparently, so they can trust the results. LLMs initially seem capable but fail to capture those extra layers of meaning. They are wildly costly to run at scale, act as black boxes, and frequently hallucinate. Modulate’s unique approach with ELMs ensures our platform can deliver precise, transparent, and cost-effective insights that businesses need for critical decisions.”
What Is an Ensemble Listening Model?
An Ensemble Listening Model is not a single, monolithic neural network. Instead, ELMs are explicitly heterogeneous: each component analyzes a completely different aspect of the input data – such as emotion, stress, deception, escalation, or synthetic voice detection for voice conversations – all fused together through a time-aligned orchestration layer.
The orchestrator aggregates these diverse signals into a coherent, explainable interpretation of what is happening in the conversation. This modular design overcomes the greatest challenges of monolithic LLMs.
From Production Success to a New Architecture
ELM architecture was first deployed to power Modulate’s voice moderation solution, ToxMod, which is used by the most popular video games, including Call of Duty, Grand Theft Auto Online, and Rainbow Six Siege. Operating in dynamic and complex voice environments, where systems must distinguish playful banter from genuine harm in real time, ToxMod delivers greater-than-human accuracy on the toughest decisions, and has to date protected hundreds of millions of conversations.
Building on that success, Modulate focused on refining the underlying engine powering ToxMod, an ELM they named Velma, which powers the Modulate platform. The result is Velma 2.0, a substantially expanded ELM capable of understanding any voice conversation and generating enterprise-ready insights about what is being said, how it is spoken, and by whom, including whether a voice is synthetic or impersonated.
Inside Velma 2.0
Velma 2.0 uses over 100 component models each meant to analyze different aspects of voice conversations, ultimately building an analysis across five layers:
- Basic Audio Processing: Determine the number of speakers in an audio clip and duration of pauses between words and speakers.
- Acoustic Signal Extraction: Emotions such as anger, approval, happiness, frustration, and stress; deception indicators; synthetic voice markers; background noise; etc.
- Perceived Intent: Differentiate speech between praise or as a sarcastic insult.
- Behavior Modeling: Identify frustration, confusion, or distraction mid-conversation. Flag attempts at social engineering for fraudulent purposes, or if the speaker is reading a script rather than speaking freely.
- Conversational Analysis: Contextual events, such as frustrated customers, policy violations, or confused AI agents.
Velma 2.0 understands the meaning and intent of voice conversations 30% more accurately than the leading LLMs, while 10-100x more cost-effective than foundation models (see the full data here).
The Ensemble Listening Model signals a new category in AI architecture, offering a compelling alternative to brute-force scaling as businesses demand faster, less expensive, and more accountable AI systems.
To learn more about Ensemble Listening Models, visit: ensemblelisteningmodel.com.
To dive deeper into what Modulate & Velma can do, visit: modulate.ai.
About Modulate
Modulate is a frontier voice intelligence AI company and the creator of Velma. First recognized for its work in video games, powering titles including Call of Duty and Grand Theft Auto Online, Modulate is the world's leader in conversational intelligence - especially when it comes to dynamic, emotive, noisy, and downright messy conversations as are the norm in the real world. To date, Modulate has provided insights into hundreds of millions of conversations, protecting tens of millions of end users from fraud, abuse, and harassment while improving efficiency, retention, and wellbeing for enterprises, call centers, and online platforms.
Visit Modulate at modulate.ai to learn more, and follow Modulate on LinkedIn and X.
Contact Information:
Madison Reardon
mreardon@wearetierone.com
A photo accompanying this announcement is available at https://www.globenewswire.com/NewsRoom/AttachmentNg/703339bf-e5bb-4b0a-b723-ac23835bef41